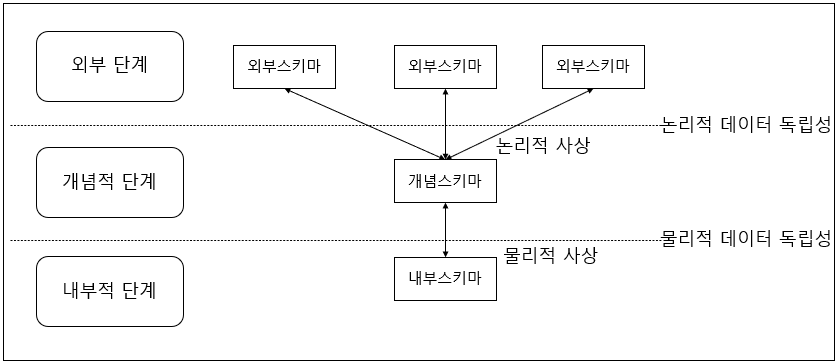
엔터티 (Entity) 란?
- 실체, 객체
- 사람, 장소, 물건, 사건, 개념 등과 같은 명사에 해당
- 업무상 관리가 필요한 것에 해당
- 저장 되기 위한 어떤 것(Thing)에 해당
엔터티의 특징
- 업무에 필요로 하는 정보여야 한다.
* 시스템 구축 대상인 해당 엄무에서 그 엔터티를 필요로 하는가를 판단하는 것이 중요
- 식별이 가능해야 한다.
* 인스턴스 각각을 구분하기 위한 유일한 식별자가 존재해야함
- 엔터티는 인스턴스의 집합이다.
* 두 개 이상의 인스턴스가 있어야함
- 엔터티는 반드시 속성을 지녀야한다.
* 관계엔터티(Associative Entity)의 경우는 주식별자 속성만 가지고 있어도 엔터티로 인정
- 엔터티는 업무 프로세스에 의해서 이용되어야 한다.
* 고립된 엔터티의 경우는 엔터티를 제거하거나 아니면 누락된 프로세스가 존재하는지 살펴보고 해당 프로세스를 추가해야 함
- 엔터티는 다른 엔터티와 최소 한개 이상의 관계가 있어야 한다.
*공통코드, 통계성 엔터티의 경우 관계를 생략할 수 있다.

엔터티의 종류
| 종류 | 설명 |
| 독립 엔티티 [Kernel Entity, Master Entity] |
사람, 물건, 장소 등과 같이 현실세계에 존재하는 엔터티 |
| 업무중심 엔터티 [Transaction Entity] |
Transaction이 실행되면서 발생하는 엔터티 |
| 종속 엔터티 [Dependent Entity] |
주로 1차 정규화로 인해 관련 중심엔티티로부터 분리된 엔터티 |
| 교차 엔티티 [Intersaction Entity] |
M:M의 관계를 해소하려는 목적으로 만들어진 엔터티 [ex> M:M -> 1:M] |
엔터티의 분류
| 분류 | 종류 | 설명 |
| 유무형에 따른 분류 | 유형 엔터티 (Tangible Entity) |
물리적 형태가 있고 지속적으로 활용되는 엔터티 예) 사원, 물품, 강사 등 |
| 개념 엔터티 (Conceptual Entity) |
물리적 형태가 없는 엔터티(개념적 정보) 예) 보험 상품, 조직 등 |
|
| 사건 엔터티 (Event Entity) |
업무를 수행함에 따라 발생되는 엔터티 예) 주문, 청구 미납 등 |
|
| 발생 시점에 따른 분류 | 기본 엔터티 (Key/Fundamental Entity) |
원래 존재하는 정보로서 다른 엔터티와 관계에 의해 성생되지 않고 독립적으로 생성, 자신의 고유한 주식별자를 가짐 예) 사원, 부서, 고객, 상품, 자재 등 |
| 중심 엔터티 (Main Entity) |
기본 엔터티로부터 발생, 다른 엔터티와의 관계로 많은 행위 엔터티 생성 예) 계약, 사고 ,청구, 주문, 매출 등 |
|
| 행위 엔터티 (Active Entity) |
2개 이상의 부모 엔터티로부터 발생, 비지니스 프로세스를 실행하면서 생성되는 엔터티, 지속적으로 정보가 추가되고 변경되어 데이터 양이 가장 많음 예) 주문 목록, 사원변경이력 등 |
엔터티의 명명(이름짓는 법)
- 업무 목적에 따라 생성되는 자연스러운 이름을 부여
- 약어보다는 명확성과 업무전달성에 목적을 두어 부여
- 명명 규칙 : 현업업무에서 사용되는 용어, 약어 지양, 단수 명사, 유일성 보장, 명확성
반응형
LIST
'Self Study > SQLD' 카테고리의 다른 글
| [SQLD] 관계(Relationship) (0) | 2022.11.02 |
|---|---|
| [SQLD] 속성(Attribute) (0) | 2022.11.02 |
| [SQLD] 데이터 모델링의 중요한 세 가지 개념 (0) | 2022.11.02 |
| [SQLD] 데이터 모델링에서에서 데이터 독립성의 이해 (0) | 2022.11.02 |
| [SQLD] 데이터 모델링의 3단계 (0) | 2022.11.02 |